
딥러닝 챗봇 정리
Chap 3. 토크나이징
토큰: 가장 기본이 되는 단어 -> 토큰 단위로 정보를 나눔
KoNLPy : 한국어 자연어처리 라이브러리 (형태소를 토큰 단위)
Kkma: 한국어 형태소 분석기 (분석 품질 좋음)
from konlpy.tag import Kkma
kkma=Kkma()
text="와, 진짜 학교 가기 싫다."
morphs=kkma.morphs(text)
print(morphs)
#형태소, 품사태그
pos=kkma.pos(text)
print(pos)
#명사 추출
nouns=kkma.nouns(text)
print(nouns)
Komoran: 자바로 개발한 한국어 형태소 분석기 (사용자 사전 관리 용이)
Chap4. 임베딩
자연어를 숫자나 벡터 형태로 변환 (단어 임베딩만 해봄)
원-핫 인코딩: 단어를 숫자 벡터로 변환
from konlpy.tag import Komoran
import numpy as np
komoran=Komoran()
text = "이 컴퓨터는 포맷이 필요해."
#명사 추출
nouns=komoran.nouns(text)
print(nouns)
#단어 사전 구축
#단어별 인덱스 부여
dics={}
for word in nouns:
if word not in dics.keys():
dics[word]=len(dics)
print(dics)
nb_classes=len(dics)
targets=list(dics.values())
one_hot_targets=np.eye(nb_classes)[targets]
print(one_hot_targets)이 문장의 noun은 컴퓨터/ 포맷/ 필요 3가지다.
각각 인덱스를 부여해서 dics에 저장한다. 각 단어 당 한 번씩만 저장한다.
원-핫 벡터는 numpy의 eye()를 이용하여 만든다. eye()는 단위행렬을 만들어준다.
sparse representaiton이다. 단어 간 유사성이 표현되지 않음
->distributed representation ( dense representation)
Word2Vec (계산량 줄어들었음)
1. CBOW : context word를 이용하여 타깃 단어를 예측
2. skip-gram: 하나의 타깃 단어를 이용해 주변 단어를 예측
: Gensim 패키지 사용
from gensim.models import Word2Vec
from konlpy.tag import Komoran
import time
#네이버 리뷰 데이터 읽어오기
def read_review_data(filename):
with open(filename,'r',encoding='UTF8') as f:
data=[line.split('\t') for line in f.read().splitlines()]
data=data[1:] #헤더는 빼고 저장
return data
start=time.time()
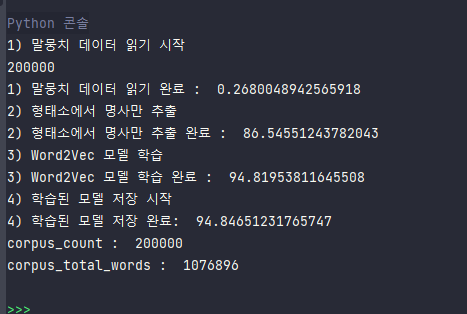
print('1) 말뭉치 데이터 읽기 시작')
review_data=read_review_data('./ratings.txt')
print(len(review_data))
print('1) 말뭉치 데이터 읽기 완료 : ',time.time()-start)
#문장 단위로 명사만 추출
print('2) 형태소에서 명사만 추출')
komoran=Komoran()
docs=[komoran.nouns(sentence[1]) for sentence in review_data]
print('2) 형태소에서 명사만 추출 완료 : ',time.time()-start)
#Word2Vec 모델 학습
print('3) Word2Vec 모델 학습')
model = Word2Vec(sentences=docs, vector_size=200, window=4, min_count=2, sg=1)
print('3) Word2Vec 모델 학습 완료 : ',time.time()-start)
# 모델 저장
print('4) 학습된 모델 저장 시작')
model.save('nvmc.model')
print('4) 학습된 모델 저장 완료: ', time.time() - start)
# 학습된 말뭉치 개수, 코퍼스 내 전체 단어 개수
print("corpus_count : ", model.corpus_count)
print("corpus_total_words : ", model.corpus_total_words)Word2Vec()의 parameter 중에 size를 vector_size로 바꿈
잘 동작함
from gensim.models import Word2Vec
# 모델 로딩
model = Word2Vec.load('nvmc.model')
print("corpus_total_words : ", model.corpus_total_words)
# 단어 유사도 계산
print("일요일 = 월요일\t", model.wv.similarity(w1='일요일', w2='월요일'))
print("안성기 = 배우\t", model.wv.similarity(w1='안성기', w2='배우'))
print("대기업 = 삼성\t", model.wv.similarity(w1='대기업', w2='삼성'))
print("일요일 != 삼성\t", model.wv.similarity(w1='일요일', w2='삼성'))
print("히어로 != 삼성\t", model.wv.similarity(w1='히어로', w2='삼성'))
# 가장 유사한 단어 추출
print(model.wv.most_similar("안성기", topn=3))
print(model.wv.most_similar("시리즈", topn=3))실제로 유사한 단어를 잘 찾아내는지 확인해보기
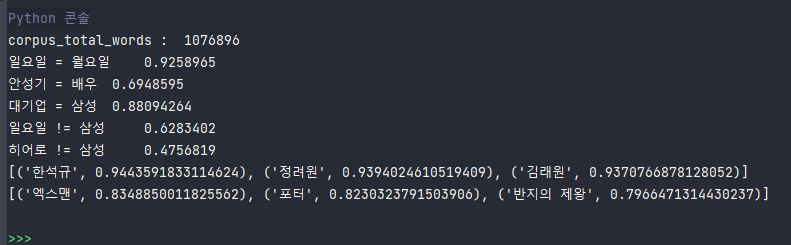
음... 일요일이랑 삼성의 유사도가 무시할 수 없는데😥
아무튼 실제로도 유사한 단어들이 그렇지 않은 단어들에 비해 유사도가 높게 나왔다.
유사한 단어 추출도 괜찮은 결과이다.
Chap 5. 텍스트 유사도
문장은 단어들의 묶음이기 때문에 하나의 벡터로 묶에서 문장간의 유사도를 계산할 수 있다.
QnA 챗봇을 개발하는 것이 목적이기 때문에 통계적인 방법을 이용해보자.
n-gram 유사도 : 문장에서 n개의 단어를 토큰으로 사용
2-gram 유사도 계산하기
from konlpy.tag import Komoran
# 어절 단위 n-gram
def word_ngram(bow, num_gram):
text = tuple(bow)
ngrams = [text[x:x + num_gram] for x in range(0, len(text))]
return tuple(ngrams)
# 음절 n-gram 분석
def phoneme_ngram(bow, num_gram):
sentence = ' '.join(bow)
text = tuple(sentence)
slen = len(text)
ngrams = [text[x:x + num_gram] for x in range(0, slen)]
return ngrams
# 유사도 계산
def similarity(doc1, doc2):
cnt = 0
for token in doc1:
if token in doc2:
cnt = cnt + 1
return cnt/len(doc1)
sentence1 = '6월에 뉴턴은 선생님의 제안으로 트리니티에 입학하였다'
sentence2 = '6월에 뉴턴은 선생님의 제안으로 대학교에 입학하였다'
sentence3 = '나는 맛있는 밥을 뉴턴 선생님과 함께 먹었습니다.'
komoran = Komoran()
bow1 = komoran.nouns(sentence1)
bow2 = komoran.nouns(sentence2)
bow3 = komoran.nouns(sentence3)
doc1 = word_ngram(bow1, 2)
doc2 = word_ngram(bow2, 2)
doc3 = word_ngram(bow3, 2)
print(doc1)
print(doc2)
print(doc3)
r1 = similarity(doc1, doc2)
r2 = similarity(doc3, doc1)
print(r1)
print(r2)
doc3,doc1은 유사하지 않은 문장이므로 유사도가 0이 나오는 것은 당연하다.
코사인 유사도: 두 벡터 간 코사인 각도를 이용해 유사도 측정

Chap 6: 챗봇 엔진에 필요한 딥러닝 모델
케라스: 신경망 모델을 구축할 수 있는 고수준 API 라이브러리
인공 신경망: 뉴런을 수학적으로 모방 (예전에 배워서 알고있음)
y=(w0x0+w1x1+w2x2)+b
입력값과 가중치를 곱해서 더한 다음 bias 로 결과값 조정
step function: 그래프 모양이 계단식
-> 결과가 너무 극단적(0or1)
->sigmoid function ->exp함수는 연산 비용이 크다
ReLU(연산비용 크지 않아 학습 속도 빠름)
back propagation: 오차가 줄어드는 방향으로 가중치를 역방향으로 갱신
'컴퓨터 > python' 카테고리의 다른 글
| [renpy] 자동으로 아래로 내려가는 엔딩크레딧 (0) | 2022.11.22 |
|---|---|
| [django] django로 갠홈 만들어서 heroku로 배포하기 (0) | 2021.09.02 |
| 파이썬 정리 (0) | 2021.02.05 |
| 허구한 날 까먹어서 튜플/집합/사전 정리해두기 (0) | 2021.01.13 |
| 파이썬 정리-2 (0) | 2020.02.25 |

